数据结构之数组与链表
聊数组和链表前,我们首先需要知道内存和如何存放数据的。内存就像大超市寄存处,寄存处有非常多的柜子。每个柜子都有标号(内存地址),柜子用来存放行李(存放数据)。取柜子里的行李时,需要知道柜子标号。
数组
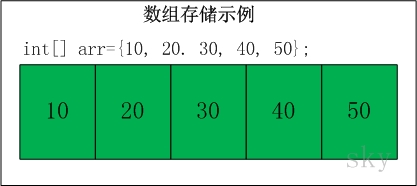
有时候我们的行李有很多,一个柜子存放不下,那么就需要使用多个柜子来存。熟悉Java的都知道,Java里的数组能够存放多个变量值。Java数组类似于一些连续在一起的柜子。
但是数组有一个非常大的缺陷,数组的长度在声明变量时就定好了。以后不可以变长也不可以缩减。在使用期间,如果数组的长度不够用了,那就要重新使用新的数组,太麻烦了。有一种策略是,声明的时候保证数组的长度足够长。但是,这样也会有两个问题:
- 数组中有许多未使用的空间,这些空间没有使用,白白浪费了
- 还是有可能长度超标的,超标后,还是需要使用新的容器来存放已有数组中的数据
链表
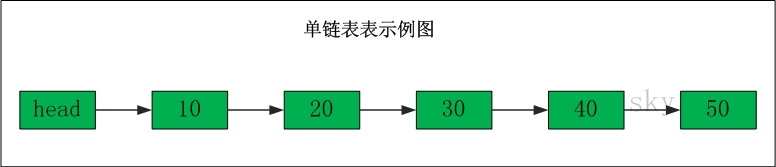
链表不同于数组,数组必须申请连续的内存空间,链表每个元素的位置是可以随意的,不必是连续的内存空间。链表中的每个元素的内存空间不是连续的,那么链表是如何知道每个元素的内存地址的呢?链表的每个元素都存储了下一个元素的地址,从而使一系列随机的内存地址串在一起。链表和数组比起来,具有动态性,不会存在长度不够的问题。
数组与链表的算法复杂度
| 数组 | 链表 | |
|---|---|---|
| 读取 | O(1) | O(n) |
| 插入 | O(n) | O(1) |
| 删除 | O(n) | O(1) |
使用Java实现单链表结构
class LinkList<T> {
/* list size */
private int size = 0;
/* the head of list */
private Node<T> head;
boolean add (T elem) {
if (head == null) {
head = new Node<>(elem);
} else {
Node<T> temp = head;
while (temp.next != null) {
temp = temp.next;
}
temp.next = new Node<>(elem);
}
size++;
return true;
}
boolean add (int index, T element) {
if (index > size | index < 0)
return false;
Node<T> temp = head;
Node<T> newNode = new Node<>(element);
if (index == 0) {
head = newNode;
head.next = temp;
} else if (size == index){
return add(element);
}else {
for (int i=1; i < index; i++) {
temp = temp.next;
}
Node<T> next = temp.next;
temp.next = newNode;
newNode.next = next;
}
size++;
return true;
}
boolean remove (int index) {
if (index >= size || index < 0)
return false;
if (index == 0) {
Node<T> next = head.next;
head = null;
head = next;
} else {
Node<T> prev = head;
for (int i = 0; i < index - 1; i++) {
prev = prev.next;
}
prev.next = prev.next.next;
}
return true;
}
T get (int index) {
if (index >= size || index < 0) {
return null;
}
Node<T> current = head;
for (int i=0; i < index; i++) {
current = current.next;
}
return current.elem;
}
void forEach () {
for (Node<T> temp = head; temp != null; temp = temp.next) {
System.out.println(temp.elem);
}
}
int size() {
return size;
}
private class Node<E extends T>
{
E elem;
Node<E> next;
Node(E elem) {
this.elem = elem;
}
}
}